Cloud Data AI Engineer

Cloud Data AI Engineer
Join a collaborative team where different perspectives strengthen how we build. Work on data and AI systems that shape real housing decisions, while growing in an environment that values ownership, curiosity, and learning.
Fulltime · Rotterdam (hybride)



About OPENRED: making an impact on the housing development of the future
OPENRED is building technology that helps tackle one of today’s biggest challenges: the housing shortage. We believe better data leads to better decisions, and that better decisions lead to more accessible, sustainable, and well-planned housing.
As a member of our engineering team, the systems you design will directly influence how housing projects are evaluated and developed. From price predictions to sustainability insights, your work becomes part of real-world decisions made by developers, municipalities, and investors.
You’ll be part of a multidisciplinary team of engineers, data scientists, and product thinkers, working closely together to turn complex data into reliable products. Our team brings together different backgrounds, nationalities, and perspectives, and we value clear thinking, ownership, and collaboration over ego.
Your role
You'll be responsible for designing, building, and maintaining the data and AI infrastructure that powers OPENRED's platform. This isn't about managing static data warehouses; it's about engineering living systems where real estate market data, sustainability scores, price predictions, and social analytics flow reliably from source to product, at scale and in near real-time.
We're in an exciting phase of our technical evolution, transitioning from a low-code environment to a modern, scalable stack. You'll play a central role in shaping that foundation together with the team — from cloud architecture and data pipelines to the AI models that drive our core features. You'll have the space to take initiative and help define how data and AI engineering are practiced at OPENRED.





Your job in a nutshell
Design, build, and maintain scalable data pipelines that ingest, transform, and serve real estate data across our platform.
Architect and manage our cloud infrastructure (GCP), ensuring reliability, cost-efficiency, and security.
Develop and deploy AI/ML models and services, including price prediction, sustainability scoring, and market analytics.
Collaborate closely with engineers and data scientists.
Take ownership of the data stack end-to-end: from ingestion and storage to transformation, serving, and monitoring.
Contribute to building a modern MLOps culture, versioning, experiment tracking, model deployment, and monitoring.
What you bring
We value diverse skill sets. If you see yourself in most of the points below, we'd love to hear from you.
3 to 7 years of experience in data engineering, cloud engineering, or a combined AI/ML engineering role.
Hands-on experience with cloud platforms (AWS, GCP, or Azure) and infrastructure-as-code tooling (e.g. Terraform, Pulumi).
Strong proficiency in Python and SQLExperience with modern data stack tooling (e.g. dbt, Airflow, Spark, Beam, or similar orchestration/transformation tools).
Familiarity with ML model development and deployment.
Bonus if you also bring:
Experience with real-time or streaming data (Kafka, Flink, or similar).
Familiarity with the real estate industry.
Familiarity with geospatial data.
Experience with LLMs and modern AI tooling (LangChain, RAG pipelines, vector databases).
Knowledge of front-end data consumption patterns (REST APIs, GraphQL).
Experience building and maintaining production-grade data pipelines.
Strong at bridging the gap between raw data and business value, translating complex model outputs into reliable, accessible product features.
Experience in B2B, SaaS, or data-intensive product environments.
Work for organisations such as:




What we offer you
A salary between €3,500 and €6,000, depending on your experience and working hours.
Available for 32+ hours.
Hybrid working model, with 2 office days
Learning and development budget.
-
A supportive, engaged team with direct communication, a culture of ownership, and annual team adventures (last year we explored Marrakesh).
We're committed to building a diverse team and welcome applications from all backgrounds. Different perspectives make our product and our team stronger.
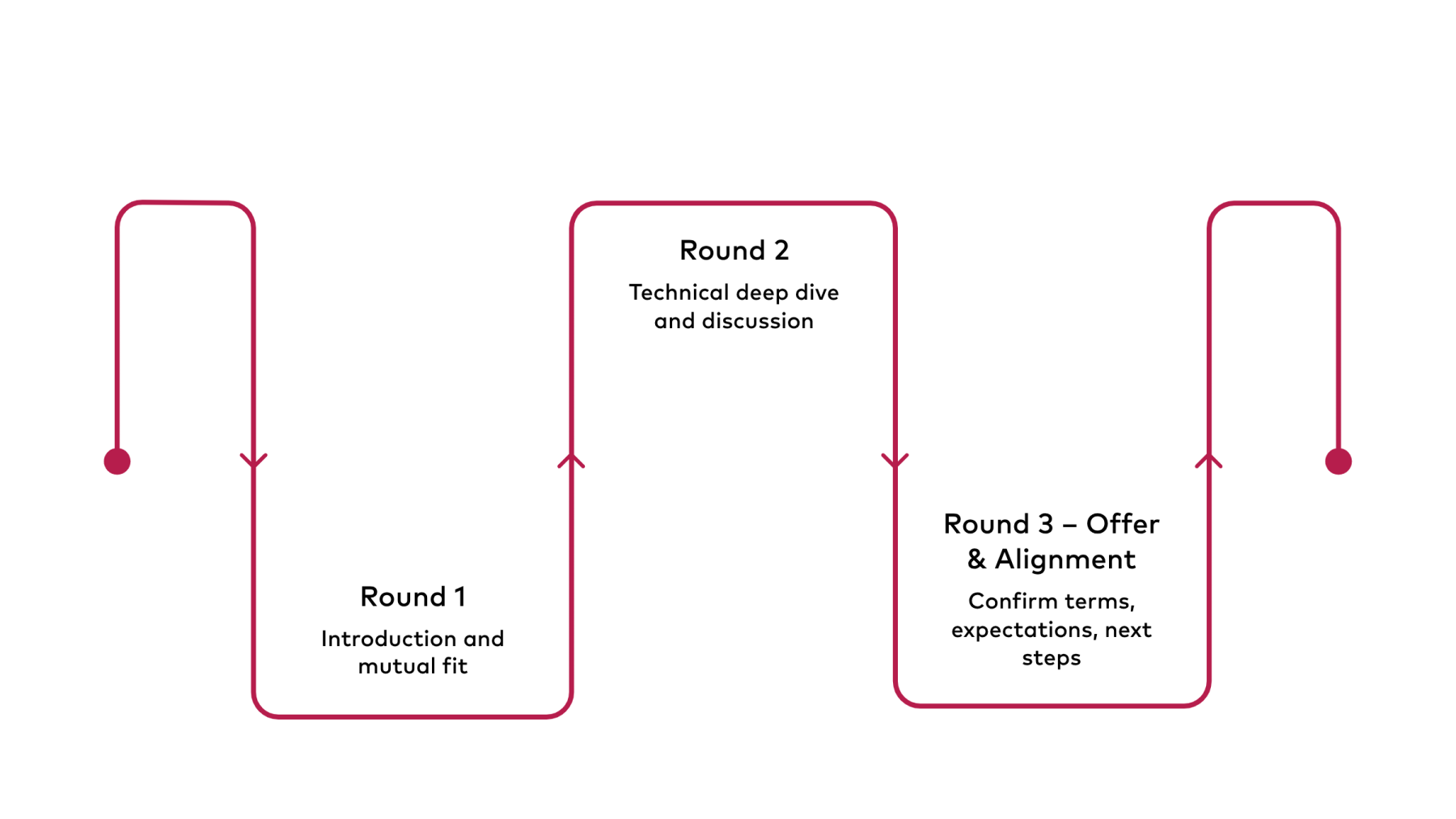
Hiring proces:
We like to keep things simple and transparent. Here’s what you can expect:
Round 1 – Introduction & mutual fit
An informal conversation where we get to know each other. We’ll talk about your experience, what excites you, and give you a clear picture of OPENRED and the role.
Round 2 – Deep dive & technical discussion
A more in-depth session with the team. We’ll go deeper into your experience with data pipelines, cloud, and AI/ML. This can include discussing past projects or walking through a practical case.
Final step – Offer & alignment
If there’s a strong match, we’ll discuss the employment terms, answer any remaining questions, and align on expectations from both sides.
We know not everyone checks every box. If this role excites you, we’d still love to hear from you.
Getting excited?
Send your CV and, if you like, share some examples of data pipelines, cloud architectures, or AI/ML projects you've worked on. Links to GitHub, a portfolio, or a short write-up all work great. Don't have a polished portfolio? No problem, just tell us what you've been working on and what you're excited about.